How IPFS Mesh Networks Eliminate Server Dependencies Through Cryptographic Content Addressing
IPFS mesh networking creates peer-to-peer content distribution where cryptographic hashes replace server locations, enabling decentralized data storage and retrieval without centralized infrastructure dependencies.


IPFS mesh networking eliminates centralized server dependencies by creating peer-to-peer content distribution networks where every participant becomes both client and server simultaneously.
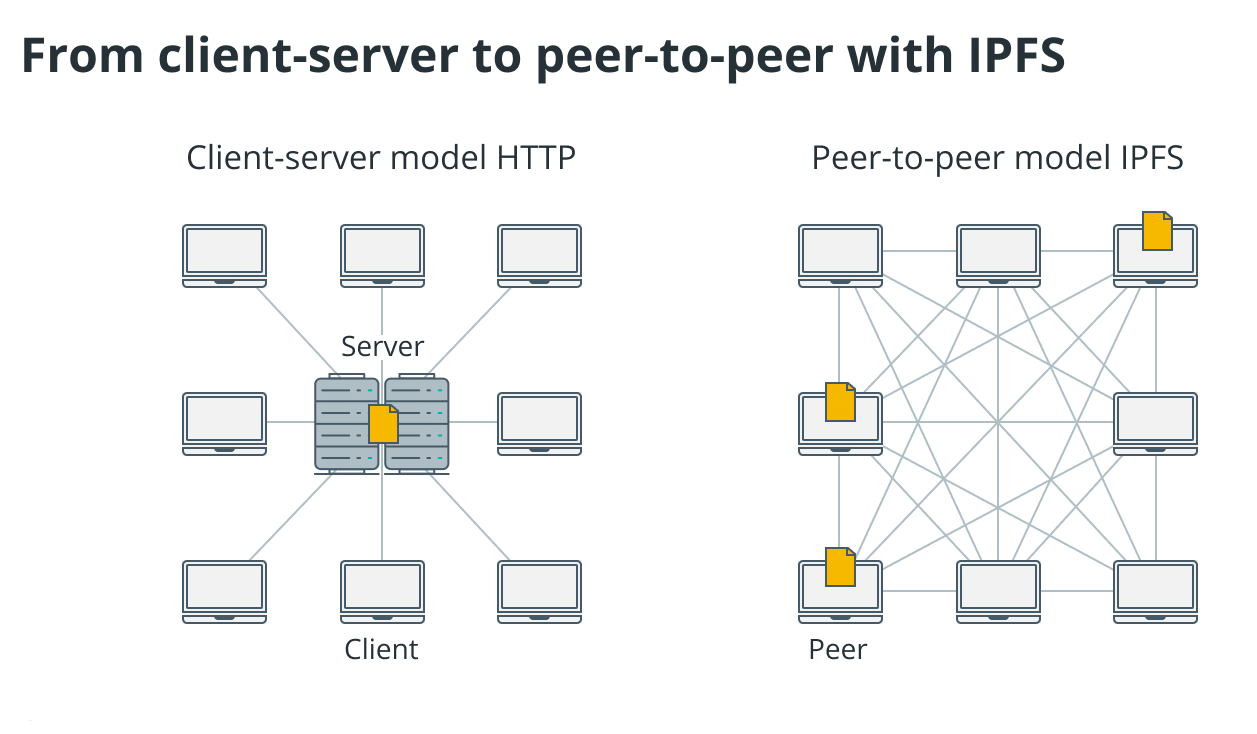
Unlike traditional web infrastructure that relies on hierarchical DNS resolution and centralized hosting, IPFS technical specification defines a content-addressed system where data location becomes irrelevant and content verification happens cryptographically through hash-based addressing that ensures data integrity without requiring trusted intermediaries.
Distributed Hash Table Architecture and Peer Discovery
IPFS implements mesh networking through a distributed hash table based on Kademlia DHT implementation that partitions the keyspace across participating nodes using consistent hashing algorithms.
Each IPFS node maintains routing tables containing peer information organized by XOR distance metrics, where nodes with IDs closer to a target key become responsible for storing and serving that content. The DHT operates through recursive lookups where nodes query progressively closer peers until they locate the target content or determine it doesn't exist in the network.
Node discovery happens through multiple mechanisms including bootstrap nodes, mDNS local discovery, and DHT crawling that builds routing tables incrementally. libp2p networking stack provides the networking foundation that handles peer discovery, connection management, and protocol negotiation across different transport layers including TCP, UDP, WebSockets, and QUIC. The mesh topology emerges naturally as nodes connect to peers based on content interests and routing optimization rather than predetermined network hierarchies.
Peer routing information gets stored in k-buckets that organize contacts by distance from the local node's ID, with each bucket containing a maximum number of peer contacts that get updated based on responsiveness and availability. The system implements exponential backoff for failed connections and maintains connection pools that balance network resource consumption against lookup performance. IPFS content addressing research demonstrates how this architecture scales to millions of nodes while maintaining sub-logarithmic lookup times.
Content Addressing and Cryptographic Verification
IPFS mesh networks use content-addressing where every piece of data gets identified by its cryptographic hash rather than location-based URLs, fundamentally changing how information gets retrieved and verified across the network.
The system generates Content Identifiers (CIDs) that combine hash functions, content encoding formats, and versioning information into self-describing addresses that remain valid regardless of where the content physically resides. This approach eliminates link rot and enables content deduplication automatically since identical data produces identical hashes.
BitSwap protocol documentation handles content exchange between peers through a want-list system where nodes advertise their content needs and respond to requests with available data blocks. The protocol implements incentive mechanisms including debt ratios that track giving-to-receiving ratios between peers, encouraging nodes to contribute content rather than only consuming it. Peers maintain ledgers tracking block exchanges and can throttle or disconnect from nodes that consistently request without providing reciprocal value.
Data integrity verification happens automatically during retrieval since content hashes enable immediate verification that received data matches the requested CID. Malicious or corrupted data gets detected instantly because hash mismatches reveal tampering or transmission errors. The mesh network achieves Byzantine fault tolerance through this cryptographic verification without requiring consensus mechanisms or trusted validators that characterize blockchain systems.
Block Storage and Merkle DAG Structures
IPFS represents complex data structures through Merkle DAG structures that break large files into content-addressed blocks linked through cryptographic hashes rather than file system pointers.
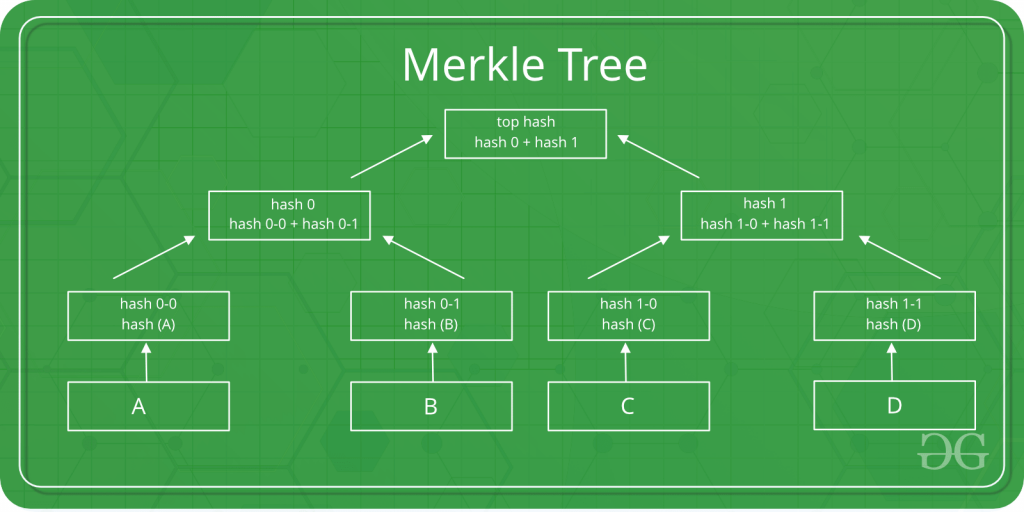
Each node stores blocks in local repositories organized by their content hashes, implementing garbage collection policies that remove unpinned content based on storage constraints and access patterns. The block storage system operates independently of traditional file systems while providing familiar directory and file abstractions through IPFS paths.
Large files get chunked into blocks typically 256KB in size, with parent nodes containing hash pointers to child blocks creating tree structures that enable parallel downloading and partial content retrieval.
The chunking strategy affects deduplication efficiency and network performance since common data patterns across different files can share identical blocks. Directory structures map to DAG nodes containing links to child files and subdirectories, preserving hierarchical organization while enabling content-addressed access patterns.
The mesh network optimizes block distribution through proximity-based caching where frequently accessed content spreads to nodes closer to requesting peers. IPFS clustering architecture coordinates multiple IPFS nodes to maintain content availability and implement replication policies that ensure data persistence without relying on any single node. The system balances storage costs against access latency by allowing nodes to specify which content they want to pin permanently versus cache temporarily.
Network Resilience and Routing Optimization
IPFS mesh networks demonstrate remarkable resilience against node failures and network partitions because content addressing enables automatic failover to alternative content sources without requiring configuration changes or manual intervention.
When nodes become unavailable, the DHT routing system automatically removes dead entries and redistributes routing responsibilities to remaining peers. Content remains accessible as long as any node in the network maintains copies, creating natural redundancy without explicit replication protocols.
The mesh topology adapts dynamically to network conditions through connection multiplexing that maintains multiple paths to popular content sources and implements intelligent peer selection based on bandwidth, latency, and historical reliability metrics. Nodes measure peer performance continuously and adjust routing preferences to optimize for local network conditions. The system handles network partitions gracefully by maintaining local content availability and reconnecting automatically when network connectivity resumes.
Performance optimization happens through content locality principles where nodes prioritize connections to peers serving relevant content, creating organic clustering around shared interests. Protocol Labs research provides extensive analysis of how these mesh properties enable IPFS networks to scale horizontally while maintaining performance characteristics that improve rather than degrade as more nodes join the network, contrary to traditional peer-to-peer systems that suffer from coordination overhead.



