How I2P Floodfill Routers Maintain Anonymous Network Databases Under Massive Peer Churn
I2P floodfill routers implement distributed hash table protocols adapted for anonymous networking, handling 20-40% hourly churn rates while maintaining network database consistency and peer discovery.

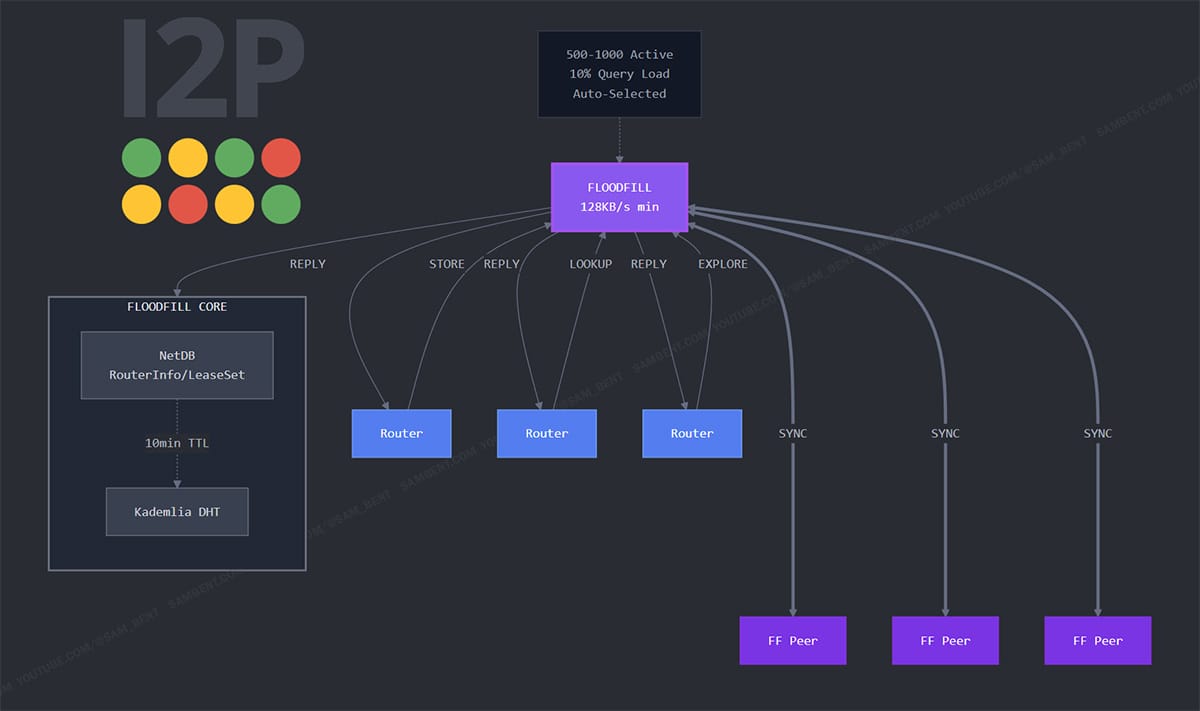
I2P floodfill routers form the backbone of anonymous networking infrastructure by maintaining distributed network databases that enable peer discovery and service location without centralized coordination or trust relationships. Unlike traditional DHT implementations that prioritize performance over anonymity, I2P network database specification demonstrates how I2P adapts distributed hash table principles to operate within strict anonymity constraints where node identities remain pseudonymous and traffic flows through layered encryption tunnels that prevent correlation analysis and traffic monitoring.
Floodfill Router Architecture and Network Database Management
Floodfill routers maintain comprehensive network databases containing RouterInfo entries that describe peer capabilities, contact information, and cryptographic keys, plus LeaseSet entries that provide temporary routing information for hidden services and client applications.
I2P router documentation details the technical requirements where floodfill routers must maintain minimum bandwidth thresholds of 128 KB/s, demonstrate network stability through continuous uptime measurements, and possess sufficient storage capacity to replicate database entries across geographically distributed network segments.
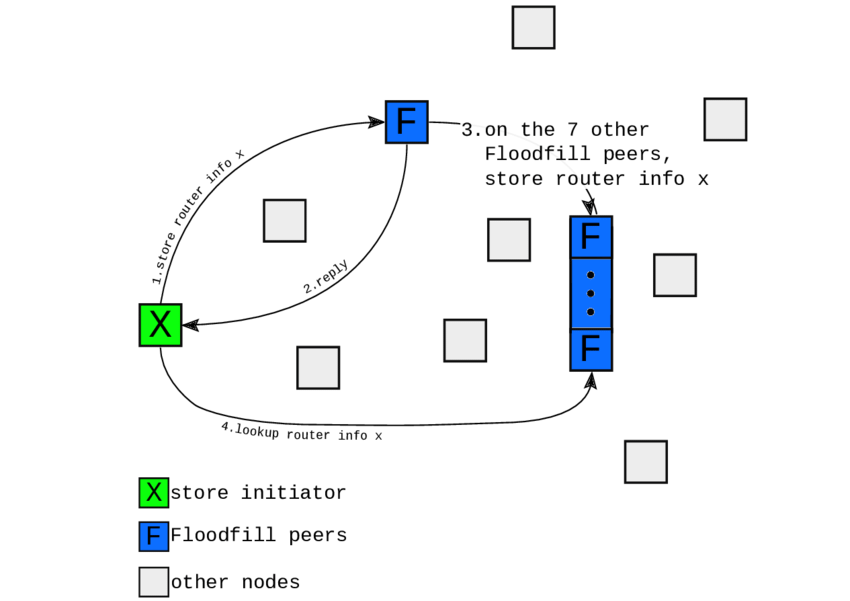
Database entry storage utilizes cryptographic hash-based addressing where each entry gets stored at multiple floodfill routers determined by XOR distance calculations between entry hashes and router identifiers. The replication factor typically ranges from 3 to 7 copies per entry depending on network size and churn rates, with higher replication used for critical infrastructure entries and popular hidden services that require enhanced availability guarantees.
Load balancing mechanisms distribute database queries across available floodfill routers using deterministic selection algorithms that prevent hot-spotting while maintaining query unlinkability. Router selection considers bandwidth capacity, geographic diversity, and historical reliability metrics to optimize both performance and censorship resistance across diverse network conditions and adversarial environments.
Network Database Propagation and Kademlia DHT Adaptation
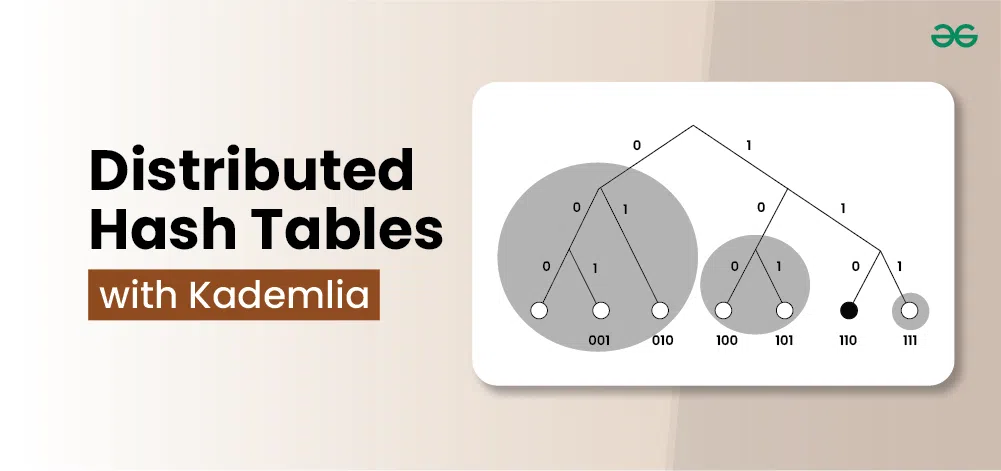
I2P implements a modified Kademlia DHT research paper distributed hash table that adapts traditional DHT protocols for anonymous networking requirements where node lookup efficiency must be balanced against traffic analysis resistance. The protocol uses XOR distance metrics to determine entry storage locations and routing paths, but incorporates random delays, dummy traffic, and tunnel-based forwarding to prevent timing correlation attacks that could compromise user anonymity.
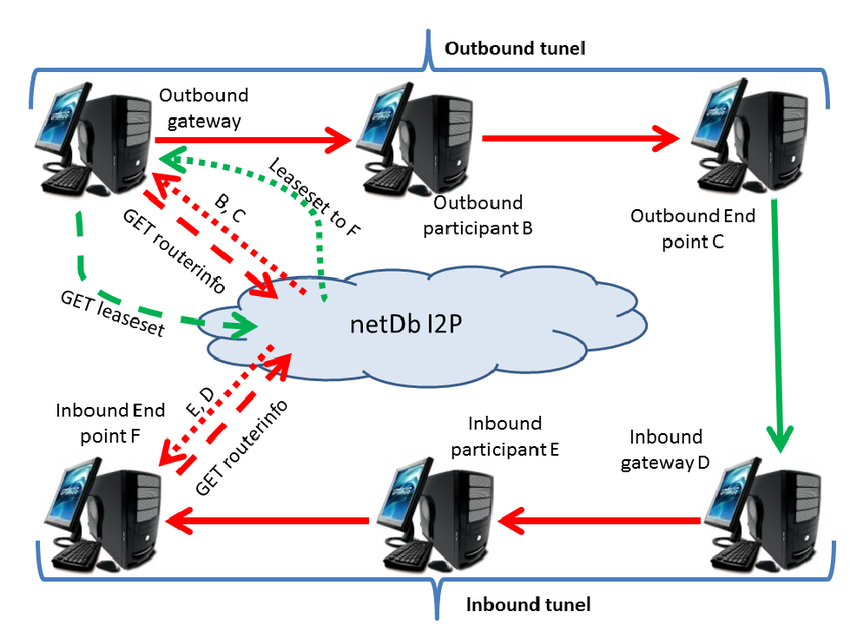
Database store operations propagate entries through multi-hop tunnel networks where publication requests get encrypted and routed through intermediary nodes before reaching target floodfill routers. I2P tunnel implementation shows how tunnel-based forwarding ensures that content publishers cannot be directly linked to specific database entries, while floodfill routers cannot determine the original source of published information.
Lookup operations implement iterative closest-node queries adapted for tunnel-based communication where each lookup step involves encrypted tunnel construction and response forwarding through different network paths. The protocol incorporates timeout mechanisms, redundant queries, and fallback procedures to maintain reliability despite the additional latency and complexity introduced by anonymity requirements.
Replication management ensures database consistency across floodfill routers through periodic synchronization, conflict resolution, and garbage collection procedures that remove expired entries while maintaining network connectivity. Entry expiration policies balance storage efficiency against service availability, with critical infrastructure entries receiving extended lifetimes and automatic renewal procedures.
Peer Discovery and Network Bootstrap Procedures
Initial peer discovery relies on reseed servers that provide cryptographically signed router information bundles containing verified peer addresses and capability announcements. New nodes download these bundles through HTTPS connections to established reseed infrastructure, then verify digital signatures and integrate peer information into local routing tables before attempting direct I2P network connections.

Dynamic peer discovery during normal operation occurs through database lookup responses, tunnel build confirmations, and periodic network database queries that reveal additional router information. I2P network statistics provides real-time network statistics showing typical discovery rates where newly joining routers identify 50-100 initial peers within the first 10 minutes of operation, gradually expanding to maintain 500-1000 known peers for optimal routing diversity.
Peer verification procedures validate router information authenticity through cryptographic signature checks, capability verification, and behavioral analysis that identifies potentially malicious or compromised nodes. The verification process includes bandwidth testing, latency measurement, and uptime tracking that enables reputation-based peer selection for critical network operations.
Network partition detection mechanisms monitor connectivity patterns and database synchronization status to identify potential network splits or eclipse attacks. Automated recovery procedures attempt alternative bootstrap sources, expand peer discovery searches, and implement backup communication channels when primary network connectivity becomes unavailable or unreliable.
Churn Resilience and Network Stability Under Dynamic Conditions
Network churn analysis reveals that I2P experiences typical peer departure rates of 20-40% per hour during normal operation, with higher churn during peak usage periods and network attacks. I2P source code repository tracks these patterns showing how floodfill router stability remains significantly higher than general peer populations, with 75% of floodfill routers maintaining continuous operation for 24+ hours compared to 25% for regular participating routers.
Adaptive replication strategies automatically adjust database entry distribution based on measured churn rates and network stability indicators. During high-churn periods, the system increases replication factors from 3 to 7 copies per entry and reduces database entry lifetimes to ensure rapid propagation of updated router information that reflects current network topology.
Failover mechanisms detect floodfill router departures through missed heartbeat messages, failed database queries, and tunnel build timeouts, automatically redistributing stored entries to backup routers selected through distance-based algorithms. The recovery process typically completes within 5-10 minutes for normal departures, with emergency procedures enabling sub-minute failover for critical infrastructure components.
Network healing procedures rebuild connectivity following large-scale departures or targeted attacks through expanded peer discovery, alternative bootstrap sources, and temporary relaxation of anonymity constraints to prioritize network connectivity. These procedures balance rapid recovery against potential security vulnerabilities introduced during network stress conditions.
Performance Optimization and Scalability Considerations
Floodfill router performance optimization focuses on database query response times, storage efficiency, and bandwidth utilization that directly impact user experience and network scalability. anonymous networking research contains implementation details showing how optimized routers can handle 1000+ database queries per minute while maintaining sub-second response times and preserving anonymity guarantees through careful resource allocation and caching strategies.
Database size management implements intelligent caching, selective replication, and priority-based storage that ensures critical network infrastructure information remains readily available while less important entries may be evicted during resource constraints. Storage optimization techniques include compression, deduplication, and hierarchical storage management that maximizes database capacity within available memory and disk resources.
Bandwidth optimization strategies include request aggregation, response caching, and intelligent prefetching that reduce redundant network traffic while maintaining database freshness and availability. Advanced implementations utilize predictive caching based on usage patterns and geographic proximity to minimize lookup latency for frequently accessed services.
Future scalability research addresses challenges associated with network growth beyond current capacity limits through protocol enhancements including sharded databases, hierarchical routing structures, and hybrid centralized-decentralized architectures. I2P protocol specifications documents ongoing research into post-quantum cryptographic integration, improved tunnel selection algorithms, and enhanced traffic analysis resistance that will enable I2P scaling to millions of simultaneous users while preserving strong anonymity guarantees.



